
Question 66
Which organization-related tasks can be performed by the ORGADMIN role? (Choose three.)
Question 67
What is a valid object hierarchy when building a Snowflake environment?
Question 68
An Architect needs to design a Snowflake account and database strategy to store and analyze large amounts of structured and semi-structured dat a. There are many business units and departments within the company. The requirements are scalability, security, and cost efficiency.
What design should be used?
What design should be used?
Question 69
A company is following the Data Mesh principles, including domain separation, and chose one Snowflake account for its data platform.
An Architect created two data domains to produce two data products. The Architect needs a third data domain that will use both of the data products to create an aggregate data product. The read access to the data products will be granted through a separate role.
Based on the Data Mesh principles, how should the third domain be configured to create the aggregate product if it has been granted the two read roles?
An Architect created two data domains to produce two data products. The Architect needs a third data domain that will use both of the data products to create an aggregate data product. The read access to the data products will be granted through a separate role.
Based on the Data Mesh principles, how should the third domain be configured to create the aggregate product if it has been granted the two read roles?
Question 70
You are creating a TASK to query a table streams created on the raw table and insert subsets of rows into multiple tables. You are following the below steps, but when you reached the step to resume the task, you received an error message as below.
Why is this error thrown and who can give you the required privilege?
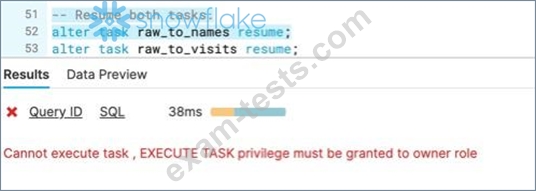
Steps to be followed to get this error
-- Create a landing table to store raw JSON data.
-- Snowpipe could load data into this table. create or replace table raw (var variant);
-- Create a stream to capture inserts to the landing table.
-- A task will consume a set of columns from this stream. create or replace stream rawstream1 on table raw;
-- Create a second stream to capture inserts to the landing table.
-- A second task will consume another set of columns from this stream. create or replace stream rawstream2 on table raw;
-- Create a table that stores the names of office visitors identified in the raw data. create or replace table names (id int, first_name string, last_name string);
-- Create a table that stores the visitation dates of office visitors identified in the raw data.
create or replace table visits (id int, dt date);
-- Create a task that inserts new name records from the rawstream1 stream into the names table
-- every minute when the stream contains records.
-- Replace the 'mywh' warehouse with a warehouse that your role has USAGE privilege on. create or replace task raw_to_names
warehouse = etl_wh
schedule = '1 minute'
when
system$stream_has_data('rawstream1')
as
merge into names n
using (select var:id id, var:fname fname, var:lname lname from rawstream1) r1 on n.id = to_number(r1.id)
when matched then update set n.first_name = r1.fname, n.last_name = r1.lname
when not matched then insert (id, first_name, last_name) values (r1.id, r1.fname, r1.lname)
;
-- Create another task that merges visitation records from the rawstream1 stream into the visits table
-- every minute when the stream contains records.
-- Records with new IDs are inserted into the visits table;
-- Records with IDs that exist in the visits table update the DT column in the table.
-- Replace the 'mywh' warehouse with a warehouse that your role has USAGE privilege on. create or replace task raw_to_visits
warehouse = etl_wh schedule = '1 minute' when
system$stream_has_data('rawstream2') as
merge into visits v
using (select var:id id, var:visit_dt visit_dt from rawstream2) r2 on v.id = to_number(r2.id) when matched then update set v.dt = r2.visit_dt
when not matched then insert (id, dt) values (r2.id, r2.visit_dt);
-- Resume both tasks.
alter task raw_to_names resume;
Why is this error thrown and who can give you the required privilege?
Steps to be followed to get this error
-- Create a landing table to store raw JSON data.
-- Snowpipe could load data into this table. create or replace table raw (var variant);
-- Create a stream to capture inserts to the landing table.
-- A task will consume a set of columns from this stream. create or replace stream rawstream1 on table raw;
-- Create a second stream to capture inserts to the landing table.
-- A second task will consume another set of columns from this stream. create or replace stream rawstream2 on table raw;
-- Create a table that stores the names of office visitors identified in the raw data. create or replace table names (id int, first_name string, last_name string);
-- Create a table that stores the visitation dates of office visitors identified in the raw data.
create or replace table visits (id int, dt date);
-- Create a task that inserts new name records from the rawstream1 stream into the names table
-- every minute when the stream contains records.
-- Replace the 'mywh' warehouse with a warehouse that your role has USAGE privilege on. create or replace task raw_to_names
warehouse = etl_wh
schedule = '1 minute'
when
system$stream_has_data('rawstream1')
as
merge into names n
using (select var:id id, var:fname fname, var:lname lname from rawstream1) r1 on n.id = to_number(r1.id)
when matched then update set n.first_name = r1.fname, n.last_name = r1.lname
when not matched then insert (id, first_name, last_name) values (r1.id, r1.fname, r1.lname)
;
-- Create another task that merges visitation records from the rawstream1 stream into the visits table
-- every minute when the stream contains records.
-- Records with new IDs are inserted into the visits table;
-- Records with IDs that exist in the visits table update the DT column in the table.
-- Replace the 'mywh' warehouse with a warehouse that your role has USAGE privilege on. create or replace task raw_to_visits
warehouse = etl_wh schedule = '1 minute' when
system$stream_has_data('rawstream2') as
merge into visits v
using (select var:id id, var:visit_dt visit_dt from rawstream2) r2 on v.id = to_number(r2.id) when matched then update set v.dt = r2.visit_dt
when not matched then insert (id, dt) values (r2.id, r2.visit_dt);
-- Resume both tasks.
alter task raw_to_names resume;