
Question 111
Your team is building a data engineering and data science development environment.
The environment must support the following requirements:
support Python and Scala
compose data storage, movement, and processing services into automated data pipelines the same tool should be used for the orchestration of both data engineering and data science support workload isolation and interactive workloads enable scaling across a cluster of machines You need to create the environment.
What should you do?
The environment must support the following requirements:
support Python and Scala
compose data storage, movement, and processing services into automated data pipelines the same tool should be used for the orchestration of both data engineering and data science support workload isolation and interactive workloads enable scaling across a cluster of machines You need to create the environment.
What should you do?
Question 112
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Question 113
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
* /data/2018/Q1.csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
All files store data in the following format:
id,f1,f2i
1,1.2,0
2,1,1,
1 3,2.1,0
You run the following code:

You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:

Solution: Run the following code:

Does the solution meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
* /data/2018/Q1.csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
All files store data in the following format:
id,f1,f2i
1,1.2,0
2,1,1,
1 3,2.1,0
You run the following code:
You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:
Solution: Run the following code:
Does the solution meet the goal?
Question 114
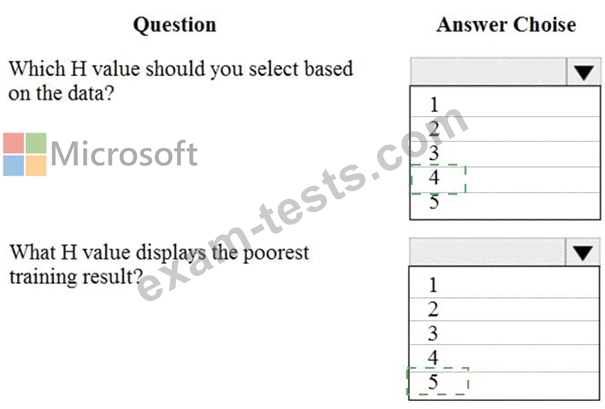
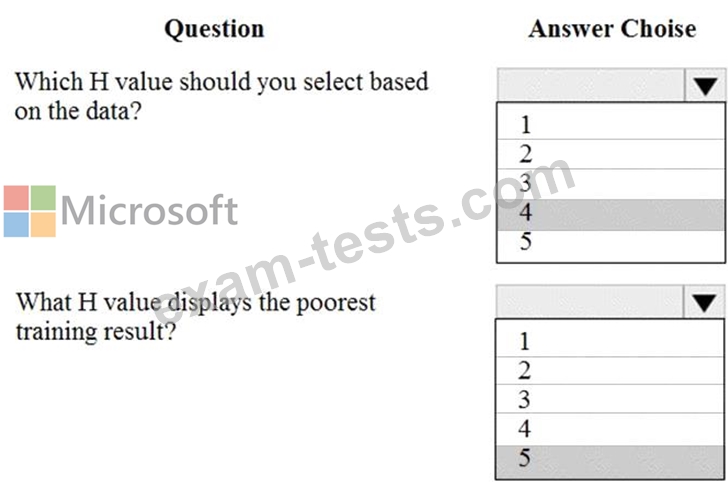
You are tuning a hyperparameter for an algorithm. The following table shows a data set with different hyperparameter, training error, and validation errors.

Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
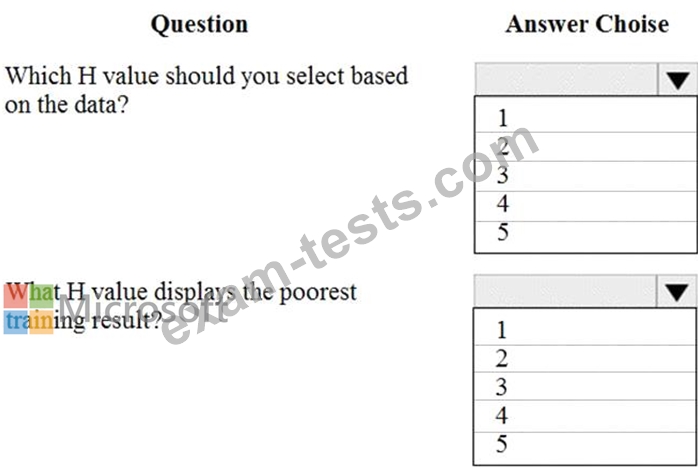
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
Question 115
You are developing a machine learning, experiment by using Azure. The following images show the input and output of a machine learning experiment:
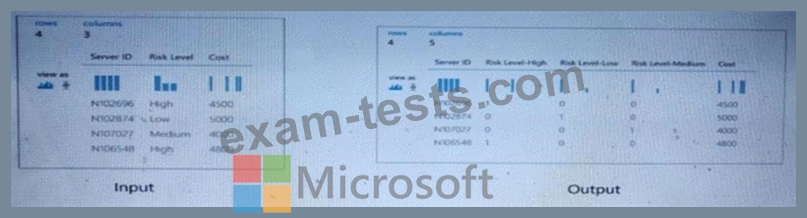
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.

Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
