You are working with a Snowflake table named 'CUSTOMER DATA' containing customer information, including a 'PHONE NUMBER' column. Due to data entry errors, some phone numbers are stored as NULL, while others are present but in various inconsistent formats (e.g., with or without hyphens, parentheses, or country codes). You want to standardize the 'PHONE NUMBER column and replace missing values using Snowpark for Python. You have already created a Snowpark DataFrame called 'customer df representing the 'CUSTOMER DATA' table. Which of the following approaches, used in combination, would be MOST efficient and reliable for both cleaning the existing data and handling future data ingestion, given the need for scalability?
Correct Answer: A,E
Options A and E provide the most robust and scalable solutions. A UDF offers flexibility and reusability for data cleaning within Snowpark (Option A). Option E leverages Snowflake's data loading capabilities to clean data during ingestion and adds a UDF for cleaning existing data providing a comprehensive approach. Using a UDF written in Python and used within Snowpark leverages the power of Python's regular expression capabilities and the distributed processing of Snowpark. Handling data transformations during ingestion with Snowflake's built- in COPY INTO with transformation is highly efficient. Option B is less scalable and maintainable for complex formatting. Option C is viable but executing SQL stored procedures from Snowpark Python loses some of the advantages of Snowpark. Option D addresses data masking not data transformation.
Question 97
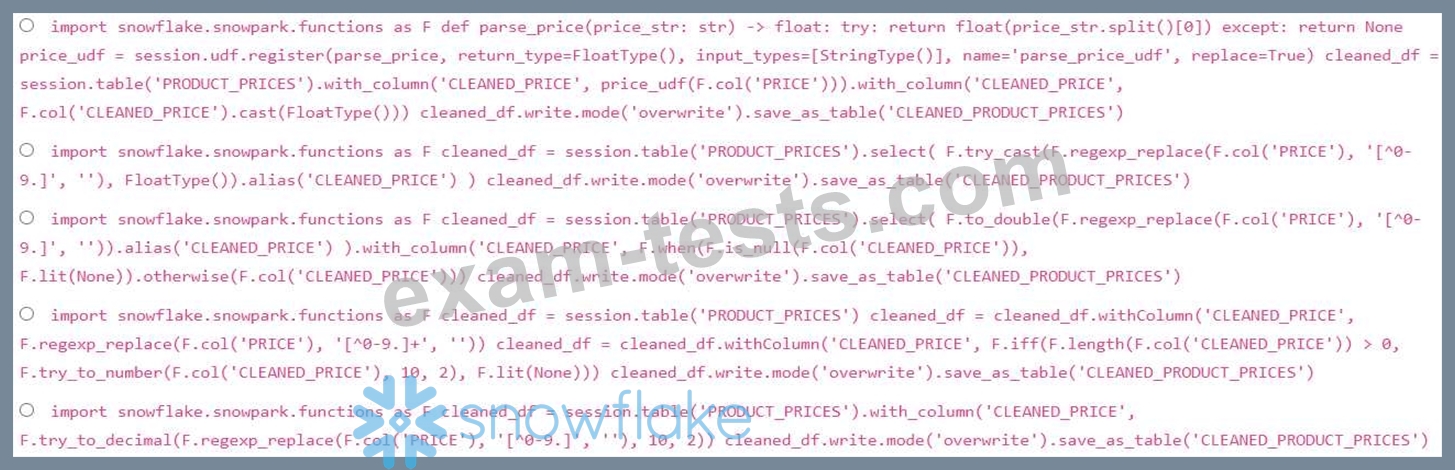
You have a Snowflake table 'PRODUCT_PRICES' with columns 'PRODUCT_ID' (INTEGER) and 'PRICE' (VARCHAR). The 'PRICE' column sometimes contains values like '10.50 USD', '20.00 EUR', or 'Invalid Price'. You need to convert the 'PRICE column to a NUMERIC(10,2) data type, removing currency symbols and handling invalid price strings by replacing them with NULL. Considering both data preparation and feature engineering, which combination of Snowpark SQL and Python code snippets achieves this accurately and efficiently, preparing the data for further analysis?
Correct Answer: E
Option E is the most efficient and accurate approach. It uses F.try_to_decimar directly in Snowpark to convert the cleaned string (after removing currency symbols using to a NUMERIC(10,2) data type. handles invalid price strings by automatically returning NULL. It avoids the overhead of UDFs and complex conditional logic, streamlining the data preparation process. Option A uses an UDF, which is less efficient than using Snowflake's built-in functions. Option B tries to cast to FloatType instead of Numeric(10,2), not meeting the requirements. Option C is similar to Option B but uses 'to_double' , which doesn't directly address the numeric precision requirement. Option D extracts all the digits and tries to do the if the length is greater than zero.
Question 98
You are using the Snowflake Python connector from within a Jupyter Notebook running in VS Code to train a model. You have a Snowflake table named 'CUSTOMER DATA' with columns 'ID', 'FEATURE 1', 'FEATURE_2, and 'TARGET. You want to efficiently load the data into a Pandas DataFrame for model training, minimizing memory usage. Which of the following code snippets is the MOST efficient way to achieve this, assuming you only need 'FEATURE 1', 'FEATURE 2, and 'TARGET' columns?
Correct Answer: B
Option B, using is the most efficient. The method directly retrieves the data as a Pandas DataFrame, leveraging Snowflake's internal optimizations for transferring data to Pandas. It's significantly faster than fetching rows individually or all at once and then creating the DataFrame. Also, it only selects the needed Columns. Option A fetches all columns and then tries to build dataframe from the list which is less effective. Option C would require additional setup with sqlalchemy and may introduce extra dependencies. Option D is also correct, but option B utilizes snowflake's internal optimizations for pandas retrieval making it best choice. Option E is also not effective as it only fetches 1000 records.
Question 99
You're building a model to predict whether a user will click on an ad (binary classification: click or no-click) using Snowflake. The data is structured and includes features like user demographics, ad characteristics, and past user interactions. You've trained a logistic regression model using SNOWFLAKE.ML and are now evaluating its performance. You notice that while the overall accuracy is high (around 95%), the model performs poorly at predicting clicks (low recall for the 'click' class). Which of the following steps could you take to diagnose the issue and improve the model's ability to predict clicks, and how would you implement them using Snowflake SQL? SELECT ALL THAT APPLY.
Correct Answer: A,B,C
A, B, and C are correct. A is necessary to understand how many false negatives and false positives exist for each label. B is the direct measures to quantify recall, precision, Fl-score and AUC. C is also a standard technique, because the original data did not capture possible non-linear relationship between features and target variables. D and E are incorrect. Simply changing to a non-linear algorthim without proper tuning does not guarantee better result. Reducing training data is unlikely to have a positive effect, as overfitting tends to occur when we have too many features compared to training data.
Question 100
You have a binary classification model deployed in Snowflake to predict customer churn. The model outputs a probability score between 0 and 1. You've calculated the following confusion matrix on a holdout set: I I Predicted Positive I Predicted Negative I --1 1 Actual Positive | 80 | 20 | I Actual Negative | 10 | 90 | What are the Precision, Recall, and Accuracy for this model, and what do these metrics tell you about the model's performance? SELECT statement given for true and false condition (True Positive, True Negative, False Positive, False Negative)
Correct Answer: C
The correct answer is C. Precision is calculated as True Positives / (True Positives + False Positives) = 80 / (80 + 10) = 0.89. Recall is calculated as True Positives / (True Positives + False Negatives) = 80 / (80 + 20) = 0.80. Accuracy is calculated as (True Positives + True Negatives) / Total = (80 + 90) / 200 = 0.85. High precision indicates fewer false positives, while lower recall indicates more false negatives. Also the select statement calculates true positives, true negatives, false positives, and false negatives from churn_predictions table and then accuracy, precision , recall has to be calculated.