
Question 31
A Nutanix cluster is deployed with the following configuration:
* Three four-node blocks (A, B, and C)
* All Flash Redundancy Factor 2
What is the effect of simultaneous disk failures on two nodes located in block A?
* Three four-node blocks (A, B, and C)
* All Flash Redundancy Factor 2
What is the effect of simultaneous disk failures on two nodes located in block A?
Question 32
An administrator needs to make sure an RF2 cluster can survive a complete rack failure without negatively effecting workload performance. The current cluster configuration consists of the following:
* 30 nodes: distributed 10 nodes per rack across three 42U rack
* Each nodes is configured with 40TB usable storage all flash (Cluster Total 1.2 PB Usable)
* Current cluster utilization is 900TB storage
Which configuration changes should be made to make sure that the cluster meets the requirements?
* 30 nodes: distributed 10 nodes per rack across three 42U rack
* Each nodes is configured with 40TB usable storage all flash (Cluster Total 1.2 PB Usable)
* Current cluster utilization is 900TB storage
Which configuration changes should be made to make sure that the cluster meets the requirements?
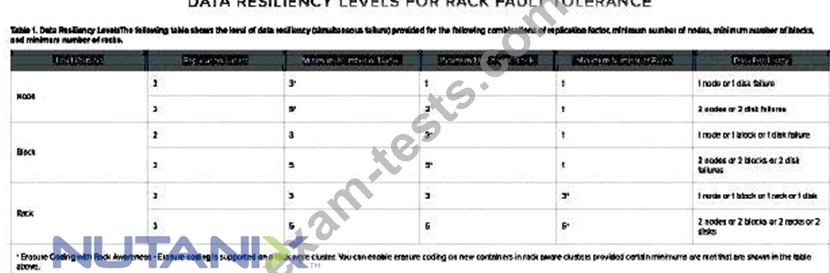
Question 33
An administrator is deploying an application that requires maximum I/O throughput for scratch data. The administrator is concerned that the throughput requirement is greater than what can be provided by a single cluster node.
What should the administrator do to meet this requirement?
What should the administrator do to meet this requirement?
Question 34
Refer to the exhibit.
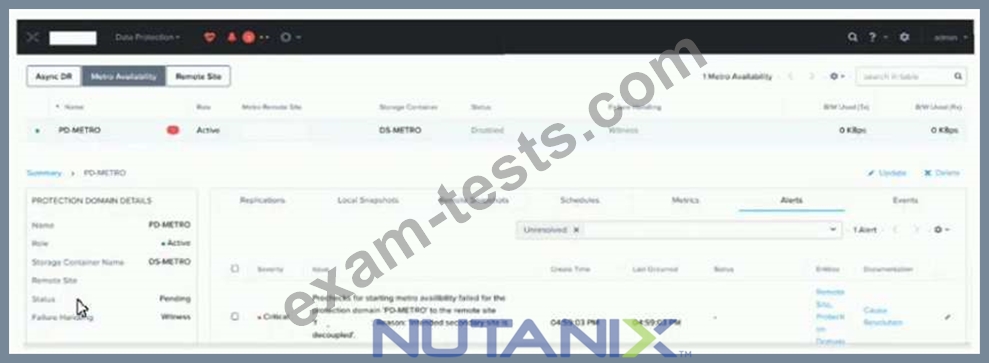
An administrator notices a critical alert on the Metro Availability Protection Domain What is causing this alert?
An administrator notices a critical alert on the Metro Availability Protection Domain What is causing this alert?
Question 35
Over the period of 2 to 3 weeks, a cluster displays the following:
*Periods where Warning Alerts of memory usage over 75% are asserted
*Periods where Critical Warnings of memory usage over 90% are asserted
*Periods of slow of frozen VDI desktops have caused work stoppage or slowdown
*VDI clones have periodically not powered up when called, causing work stoppage Which steps should be used to prioritize the administrator's troubleshooting efforts?
*Periods where Warning Alerts of memory usage over 75% are asserted
*Periods where Critical Warnings of memory usage over 90% are asserted
*Periods of slow of frozen VDI desktops have caused work stoppage or slowdown
*VDI clones have periodically not powered up when called, causing work stoppage Which steps should be used to prioritize the administrator's troubleshooting efforts?