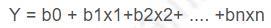What is the best way to evaluate the quality of the model found by an unsupervised algorithm like k-means clustering, given metrics for the cost of the clustering (how well it fits the data) and its stability (how similar the clusters are across multiple runs over the same data)?
Correct Answer: A
Explanation There is a tradeoff between cost and stability in unsupervised learning. The more tightly you fit the data, the less stable the model will be, and vice versa. The idea is to find a good balance with more weight given to the cost. Typically a good approach is to set a stability threshold and select the model that achieves the lowest cost above the stability threshold.
Question 2
A fruit may be considered to be an apple if it is red, round, and about 3" in diameter. A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the
Correct Answer: C
Explanation In simple terms, a naive Bayes classifier assumes that the value of a particular feature is unrelated to the presence or absence of any other feature, given the class variable. For example, a fruit may be considered to be an apple if it is red, round, and about 3" in diameter A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the presence or absence of the other features.
Question 3
You are creating a regression model with the input income, education and current debt of a customer, what could be the possible output from this model.
Correct Answer: C
Explanation Regression is the process of using several inputs to produce one or more outputs. For example The input might be the income, education and current debt of a customer The output might be the probability, expressed as a percent that the customer will default on a loan. Contrast this to classification where the output is not a number, but a class.
Question 4
Which method is used to solve for coefficients bO, b1, ... bn in your linear regression model:
Correct Answer: C
Explanation : RY = b0 + b1x1+b2x2+ .... +bnxn In the linear model, the bi's represent the unknown p parameters. The estimates for these unknown parameters are chosen so that, on average, the model provides a reasonable estimate of a person's income based on age and education. In other words, the fitted model should minimize the overall error between the linear model and the actual observations. Ordinary Least Squares (OLS) is a common technique to estimate the parameters
Question 5
Select the sequence of the developing machine learning applications A) Analyze the input data B) Prepare the input data C) Collect data D) Train the algorithm E) Test the algorithm F) Use It
Correct Answer: D
Explanation 1 Collect data. You could collect the samples by scraping a website and extracting data: or you could get information from an RSS feed or an API. You could have a device collect wind speed measurements and send them to you, or blood glucose levels, or anything you can measure. The number of options is endless. To save some time and effort you could use publicly available data 2 Prepare the input data. Once you have this data, you need to make sure it's in a useable format. The format we'll be using in this book is the Python list. We'll talk about Python more in a little bit, and lists are reviewed in appendix A. The benefit of having this standard format is that you can mix and match algorithms and data sources. You may need to do some algorithm-specific formatting here. Some algorithms need features in a special format, some algorithms can deal with target variables and features as strings, and some need them to be integers. We'll get to this later but the algorithm-specific formatting is usually trivial compared to collecting data. 3 Analyze the input data. This is looking at the data from the previous task. This could be as simple as looking at the data you've parsed in a text editor to make sure steps 1 and 2 are actually working and you don't have a bunch of empty values. You can also look at the data to see if you can recognize any patterns or if there's anything obvious^ such as a few data points that are vastly different from the rest of the set. Plotting data in one: two, or three dimensions can also help. But most of the time you'll have more than three features, and you can't easily plot the data across all features at one time. You could, however use some advanced methods we'll talk about later to distill multiple dimensions down to two or three so you can visualize the data. 4 If you're working with a production system and you know what the data should look like, or you trust its source: you can skip this step. This step takes human involvement, and for an automated system you don't want human involvement. The value of this step is that it makes you understand you don't have garbage coming in. 5 Train the algorithm. This is where the machine learning takes place. This step and the next step are where the "core" algorithms lie, depending on the algorithm.You feed the algorithm good clean data from the first two steps andextract knowledge or information. This knowledge you often store in a formatthat's readily useable by a machine for the next two steps.In the case of unsupervised learning, there's no training step because youdon't have a target value. Everything is used in the next step. 6 Test the algorithm. This is where the information learned in the previous step isput to use. When you're evaluating an algorithm, you'll test it to see how well itdoes. In the case of supervised learning, you have some known values you can use to evaluate the algorithm. In unsupervised learning, you may have to use some other metrics to evaluate the success. In either case, if you're not satisfied, you can go back to step 4, change some things, and try testing again. Often thecollection or preparation of the data may have been the problem, and you'll have to go back to step 1. 7 Use it. Here you make a real program to do some task, and once again you see if all the previous steps worked as you expected. You might encounter some new data and have to revisit steps 1-5.