What is the MuleSoft-recommended best practice to share the connector and configuration information among the APIs?
Correct Answer: A
The MuleSoft-recommended best practice for sharing the connector and configuration information among multiple APIs is to use a Mule domain project. The steps are: * Create a Mule domain project. * Add the Database connector and its configuration to the domain project. * Reference this domain project from each System API that needs to use the Database connector and configuration. By using a domain project, you centralize the configuration and reuse it across multiple APIs. This approach ensures consistency, reduces duplication, and simplifies maintenance and updates to the connector configuration. References * MuleSoft Documentation on Domain Projects * Best Practices for Reusable Configuration in MuleSoft
Question 112
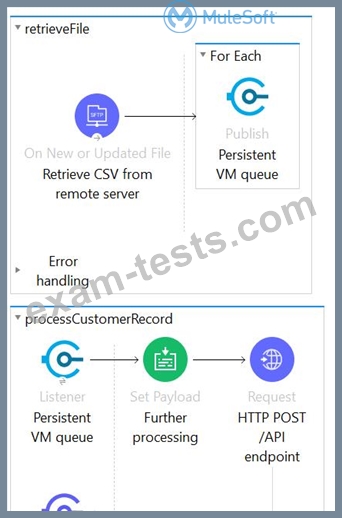
Refer to the exhibit. This Mule application is deployed to multiple Cloudhub workers with persistent queue enabled. The retrievefile flow event source reads a CSV file from a remote SFTP server and then publishes each record in the CSV file to a VM queue. The processCustomerRecords flow's VM Listner receives messages from the same VM queue and then processes each message separately. How are messages routed to the cloudhub workers as messages are received by the VM Listener?
Correct Answer: B
Question 113
Mule applications need to be deployed to CloudHub so they can access on-premises database systems. These systems store sensitive and hence tightly protected data, so are not accessible over the internet. What network architecture supports this requirement?
Correct Answer: A
* "Relocation of the database systems to a DMZ in the on-premises network, with Mule applications deployed to the CloudHub Shared Worker Cloud connecting only to the DMZ" is not a feasible option * "Static IP addresses for the Mule applications deployed to the CloudHub Shared Worker Cloud, plus matching firewall rules and IP whitelisting in the on-premises network" - It is risk for sensitive data. - Even if you whitelist the database IP on your app, your app wont be able to connect to the database so this is also not a feasible option * "An Anypoint VPC with one Dedicated Load Balancer fronting each on-premises database system, plus matching IP whitelisting in the load balancer and firewall rules in the VPC and on-premises network" Adding one VPC with a DLB for each backend system also makes no sense, is way too much work. Why would you add a LB for one system. * Correct answer: "An Anypoint VPC connected to the on-premises network using an IPsec tunnel or AWS DirectConnect, plus matching firewall rules in the VPC and on-premises network" IPsec Tunnel You can use an IPsec tunnel with network-to-network configuration to connect your on-premises data centers to your Anypoint VPC. An IPsec VPN tunnel is generally the recommended solution for VPC to on-premises connectivity, as it provides a standardized, secure way to connect. This method also integrates well with existing IT infrastructure such as routers and appliances. Reference: https://docs.mulesoft.com/runtime-manager/vpc-connectivity-methods-concept
Question 114
According to MuleSoft, what is a major distinguishing characteristic of an application network in relation to the integration of systems, data, and devices?
Correct Answer: B
A major distinguishing characteristic of an application network, according to MuleSoft, is that it is built for change and self-service. An application network connects applications, data, and devices with APIs, enabling self-service access and reuse of assets. This architecture allows organizations to rapidly adapt to changing business needs, fosters innovation, and reduces time to market by empowering different teams to access and integrate systems independently without waiting for centralized IT. References: * Application Networks: The Future of Integration * MuleSoft's Approach to Building Application Networks
Question 115
A new Mule application under development must implement extensive data transformation logic. Some of the data transformation functionality is already available as external transformation services that are mature and widely used across the organization; the rest is highly specific to the new Mule application. The organization follows a rigorous testing approach, where every service and application must be extensively acceptance tested before it is allowed to go into production. What is the best way to implement the data transformation logic for this new Mule application while minimizing the overall testing effort?
Correct Answer: D
Correct answer is Implement transformation logic in the new Mule application using DataWeave, invoking existing transformation services when possible. * The key here minimal testing effort, "Extend existing transformation logic" is not a feasible option because additional functionality is highly specific to the new Mule application so it should not be a part of commonly used functionality. So this option is ruled out. * "Implement transformation logic in the new Mule application using DataWeave, replicating the transformation logic of existing transformation services" Replicating the transformation logic of existing transformation services will cause duplicity of code. So this option is ruled out. * "Implement and expose all transformation logic as microservices using DataWeave, so it can be reused by any application component that needs it, including the new Mule application" as question specifies that the transformation is app specific and wont be used outside