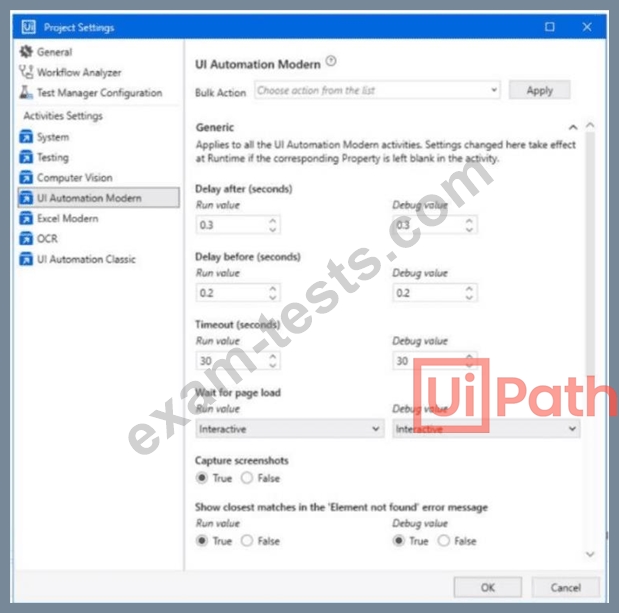
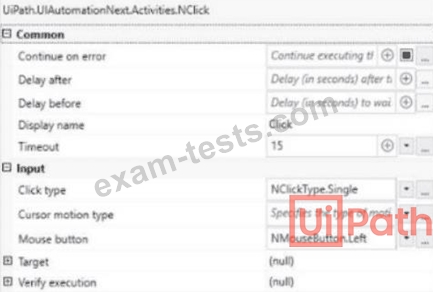
A developer configured the UI Automation Project Settings and the Properties of a Click activity as shown in the following exhibits: If the target element is not found during execution in Run mode, how long will it take until anerror is thrown (based on default project settings)?
Correct Answer: C
Comprehensive and Detailed Explanation From Exact Extract: In UiPath, when executing an activity such asClick, the timeout behavior is determined as follows: * If the Timeout property in the activity is set, that value is used. * If the Timeout is left blank, the system uses thedefault from Project SettingsunderUI Automation Modern # Timeout. In this case (based on the second image): * TheClick activity explicitly has Timeout set to 15 seconds. * Therefore, this activity willoverridethe project-level default timeout (which is 30 seconds as seen in the first image). Rule Applied: Activity Timeout > Project Settings Timeout (if defined) Hence, if thetarget element is not found, UiPath willwait for 15 seconds, as specified in the activity's Timeout field, before throwing an error. * UiPath Documentation Reference:TimeoutMS Property - UiPath Docs
Question 12
The "Train" stage from Document Understanding Framework usually comes after?
Correct Answer: C
Reference: UiPath Document Understanding Workflow
Question 13
Which of the following is a best practice when choosing a UiPath ML (Machine Learning) Extractor?
Correct Answer: B
The best practice is to select an ML Extractor based on document types, language, and data quality. Choosing a model specifically optimized for the type of document being processed ensures higher accuracy and reliability. The quality and diversity of the training data used to develop the model play a significant role in its performance. Reference: UiPath ML Extractors
Question 14
Which of the following is a best practice when choosing a UiPath ML (Machine Learning) Extractor?
Correct Answer: B
The ML Extractor is a data extraction tool that uses machine learning models provided by UiPath to identify and extract data from documents. The ML Extractor can work with predefined document types, such as invoices, receipts, purchase orders, and utility bills, or with custom document types that are trained using the Data Manager and the Machine Learning Classifier Trainer12. According to the best practice, the ML Extractor should be chosen based on the document types, language, and data quality of the documents being processed. It is important to select an ML Extractor that is specifically trained or optimized for the document types that are relevant for the use case, as different document types may have different layouts, fields, and formats. It is also important to take into account the language of the documents, as some ML Extractors may support only certain languages or require specific language settings. Moreover, it is important to consider the quality and diversity of the training data used to train the ML Extractor, as this may affect the accuracy and reliability of the extraction results. The training data should be representative of the real-world data, and should cover various scenarios, variations, and exceptions3. References: 1: Machine Learning Extractor - UiPath Activities 2: Machine Learning Classifier Trainer - UiPath Document Understanding 3: Data Extraction - UiPath Document Understanding
Question 15
Which UiPath Communications Mining model performance factor assesses the proportion of the entire dataset that has informative label predictions?
Correct Answer: B
According to the UiPath Communications Mining documentation, coverage is one of the four main factors that contribute to the model rating, which is a holistic measure of the model's performance and health. Coverage assesses the proportion of the entire dataset that has informative label predictions, meaning that the predicted labels are not generic or irrelevant. Coverage is calculated as the percentage of verbatims (communication units) that have at least one informative label out of the total number of verbatims in the dataset. A high coverage indicates that the model is able to capture the main topics and intents of the communications, while a low coverage suggests that the model is missing important information or producing noisy predictions. References: Communications Mining - Understanding and improving model performance Communications Mining - Model Rating Communications Mining - It's All in the Numbers - Assessing Model Performance with Metrics