
Question 106
A member of the data engineering team has submitted a short notebook that they wish to schedule as part of a larger data pipeline. Assume that the commands provided below produce the logically correct results when run as presented.
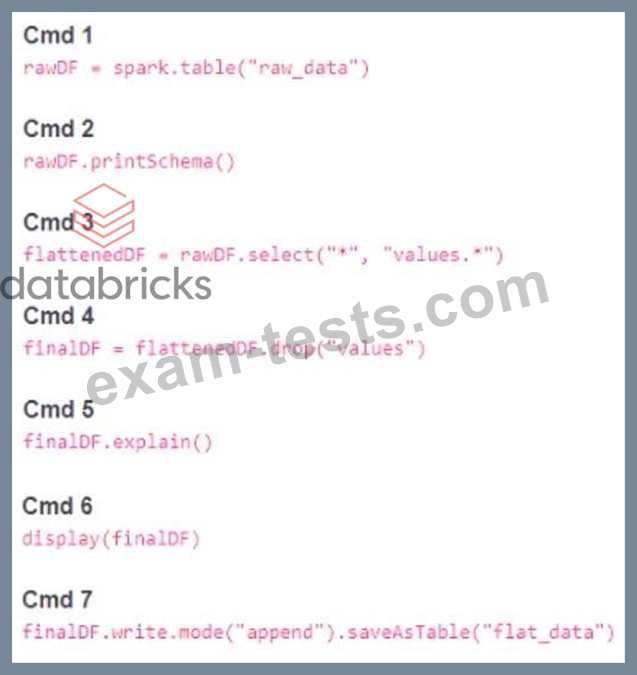
Which command should be removed from the notebook before scheduling it as a job?
Which command should be removed from the notebook before scheduling it as a job?
Question 107
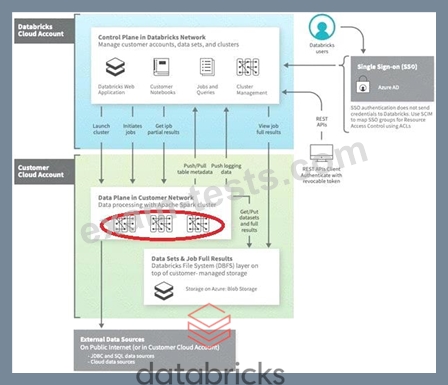
Which of the following locations hosts the driver and worker nodes of a Databricks-managed clus-ter?
Question 108
How do you handle failures gracefully when writing code in Pyspark, fill in the blanks to complete the below statement
1._____
2.
3. Spark.read.table("table_name").select("column").write.mode("append").SaveAsTable("new_table_name")
4.
5._____
6.
7. print(f"query failed")
1._____
2.
3. Spark.read.table("table_name").select("column").write.mode("append").SaveAsTable("new_table_name")
4.
5._____
6.
7. print(f"query failed")
Question 109
A data engineer is designing an append-only pipeline that needs to handle both batch and streaming data in Delta Lake. The team wants to ensure that the streaming component can efficiently track which data has already been processed.
Which configuration should be set to enable this?
Which configuration should be set to enable this?
Question 110
The data governance team has instituted a requirement that all tables containing Personal Identifiable Information (PH) must be clearly annotated. This includes adding column comments, table comments, and setting the custom table property"contains_pii" = true.
The following SQL DDL statement is executed to create a new table:
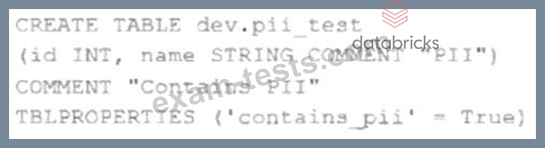
Which command allows manual confirmation that these three requirements have been met?
The following SQL DDL statement is executed to create a new table:
Which command allows manual confirmation that these three requirements have been met?
Premium Bundle
Newest Databricks-Certified-Professional-Data-Engineer Exam PDF Dumps shared by BraindumpsPass.com for Helping Passing Databricks-Certified-Professional-Data-Engineer Exam! BraindumpsPass.com now offer the updated Databricks-Certified-Professional-Data-Engineer exam dumps, the BraindumpsPass.com Databricks-Certified-Professional-Data-Engineer exam questions have been updated and answers have been corrected get the latest BraindumpsPass.com Databricks-Certified-Professional-Data-Engineer pdf dumps with Exam Engine here: