
Question 126
An analytics team wants to run a short-term experiment in Databricks SQL on the customer transactions Delta table (about 20 billion records) created by the data engineering team. Which strategy should the data engineering team use to ensure minimal downtime and no impact on the ongoing ETL processes?
Question 127
A new data engineer notices that a critical field was omitted from an application that writes its Kafka source to Delta Lake. This happened even though the critical field was in the Kafka source. That field was further missing from data written to dependent, long-term storage. The retention threshold on the Kafka service is seven days. The pipeline has been in production for three months.
Which describes how Delta Lake can help to avoid data loss of this nature in the future?
Which describes how Delta Lake can help to avoid data loss of this nature in the future?
Question 128
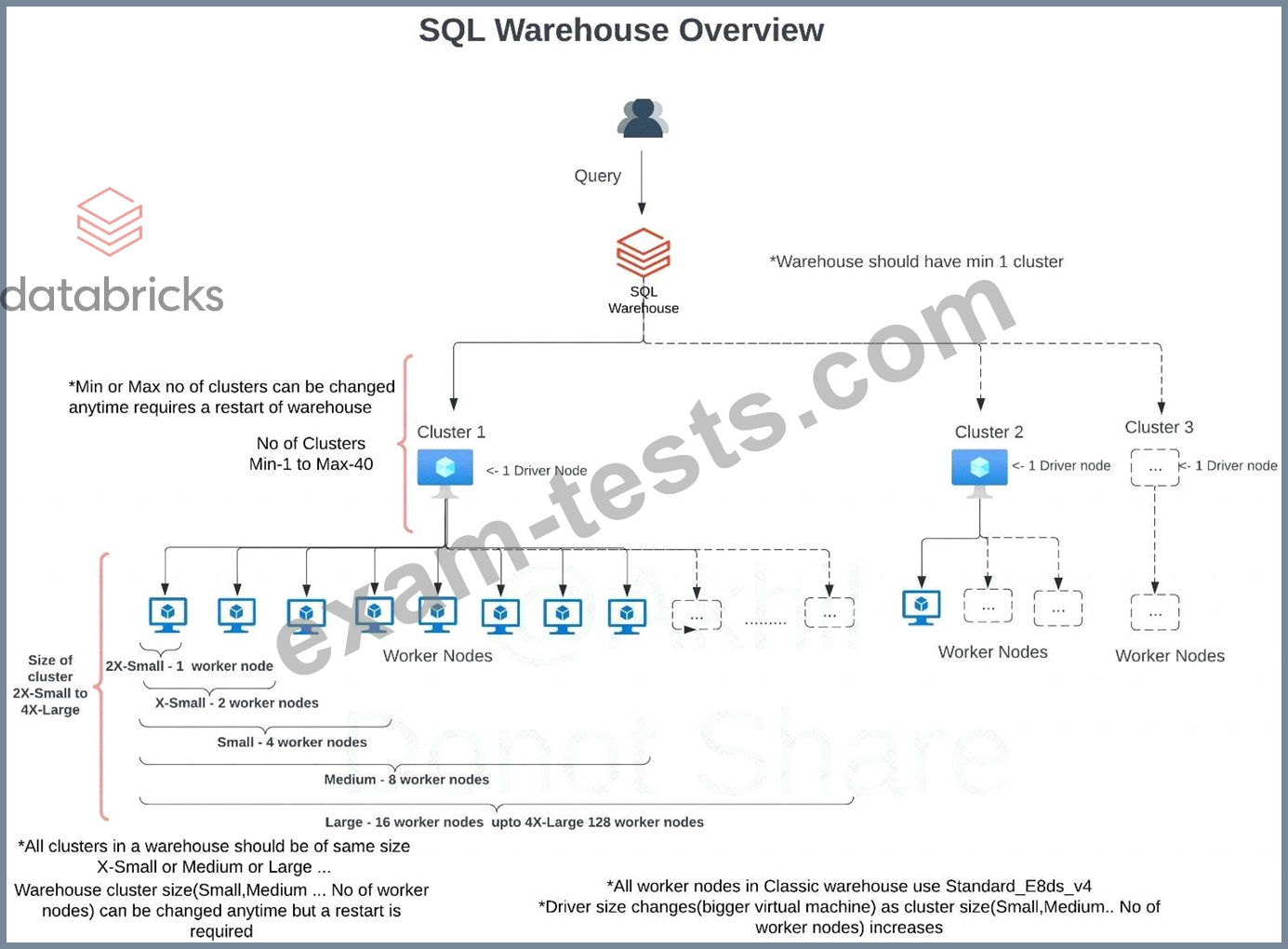
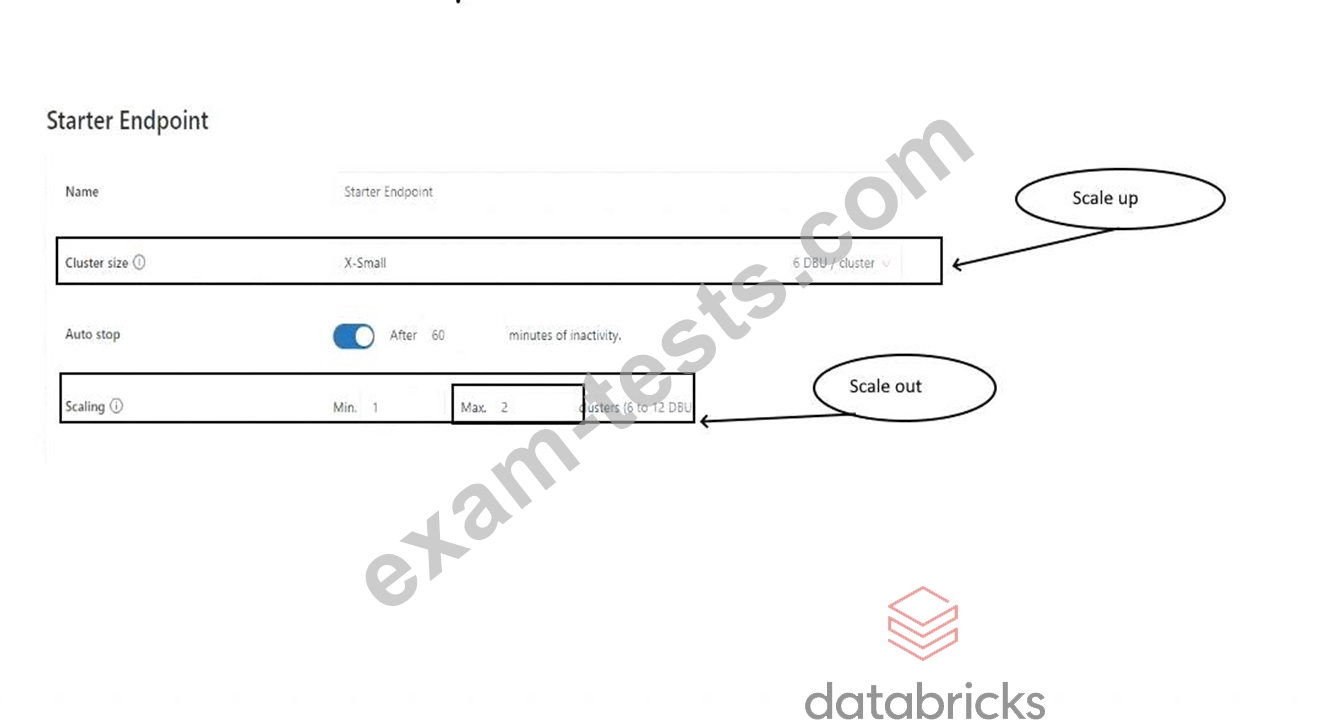
The research team has put together a funnel analysis query to monitor the customer traffic on the e-commerce platform, the query takes about 30 mins to run on a small SQL endpoint cluster with max scaling set to 1 cluster. What steps can be taken to improve the performance of the query?
Question 129
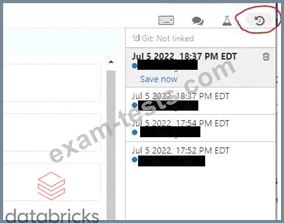
You noticed that colleague is manually copying the notebook with _bkp to store the previous ver-sions, which of the following feature would you recommend instead.
Question 130
A data engineer is configuring a Lakeflow Declarative Pipeline to process CDC (Change Data Capture) data from a source. The source events sometimes arrive out of order, and multiple updates may occur with the same update_timestamp but with different update_sequence_id.
What should the data engineer do to ensure events are sequenced correctly?
What should the data engineer do to ensure events are sequenced correctly?