
Question 86
You want to rebuild your ML pipeline for structured data on Google Cloud. You are using PySpark to conduct data transformations at scale, but your pipelines are taking over 12 hours to run. To speed up development and pipeline run time, you want to use a serverless tool and SQL syntax. You have already moved your raw data into Cloud Storage. How should you build the pipeline on Google Cloud while meeting the speed and processing requirements?
Question 87
You are developing an ML model that uses sliced frames from video feed and creates bounding boxes around specific objects. You want to automate the following steps in your training pipeline: ingestion and preprocessing of data in Cloud Storage, followed by training and hyperparameter tuning of the object model using Vertex AI jobs, and finally deploying the model to an endpoint. You want to orchestrate the entire pipeline with minimal cluster management. What approach should you use?
Question 88
You are going to train a DNN regression model with Keras APIs using this code:
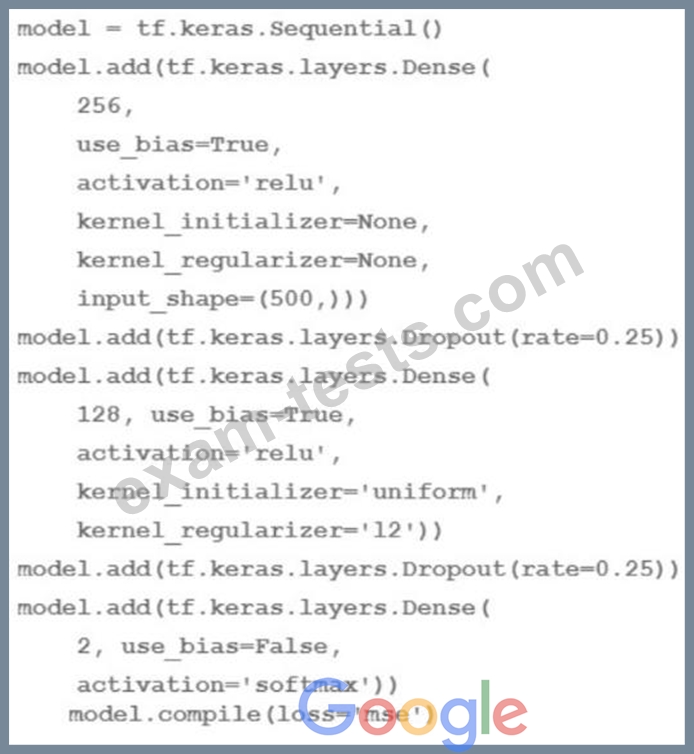
How many trainable weights does your model have? (The arithmetic below is correct.)
How many trainable weights does your model have? (The arithmetic below is correct.)
Question 89
You have developed an AutoML tabular classification model that identifies high-value customers who interact with your organization's website.
You plan to deploy the model to a new Vertex Al endpoint that will integrate with your website application. You expect higher traffic to the website during nights and weekends. You need to configure the model endpoint's deployment settings to minimize latency and cost. What should you do?
You plan to deploy the model to a new Vertex Al endpoint that will integrate with your website application. You expect higher traffic to the website during nights and weekends. You need to configure the model endpoint's deployment settings to minimize latency and cost. What should you do?
Question 90
You are creating a model training pipeline to predict sentiment scores from text-based product reviews. You want to have control over how the model parameters are tuned, and you will deploy the model to an endpoint after it has been trained You will use Vertex Al Pipelines to run the pipeline You need to decide which Google Cloud pipeline components to use What components should you choose?