You are asked to setup two tasks in a databricks job, the first task runs a notebook to download the data from a remote system, and the second task is a DLT pipeline that can process this data, how do you plan to configure this in Jobs UI
Correct Answer: D
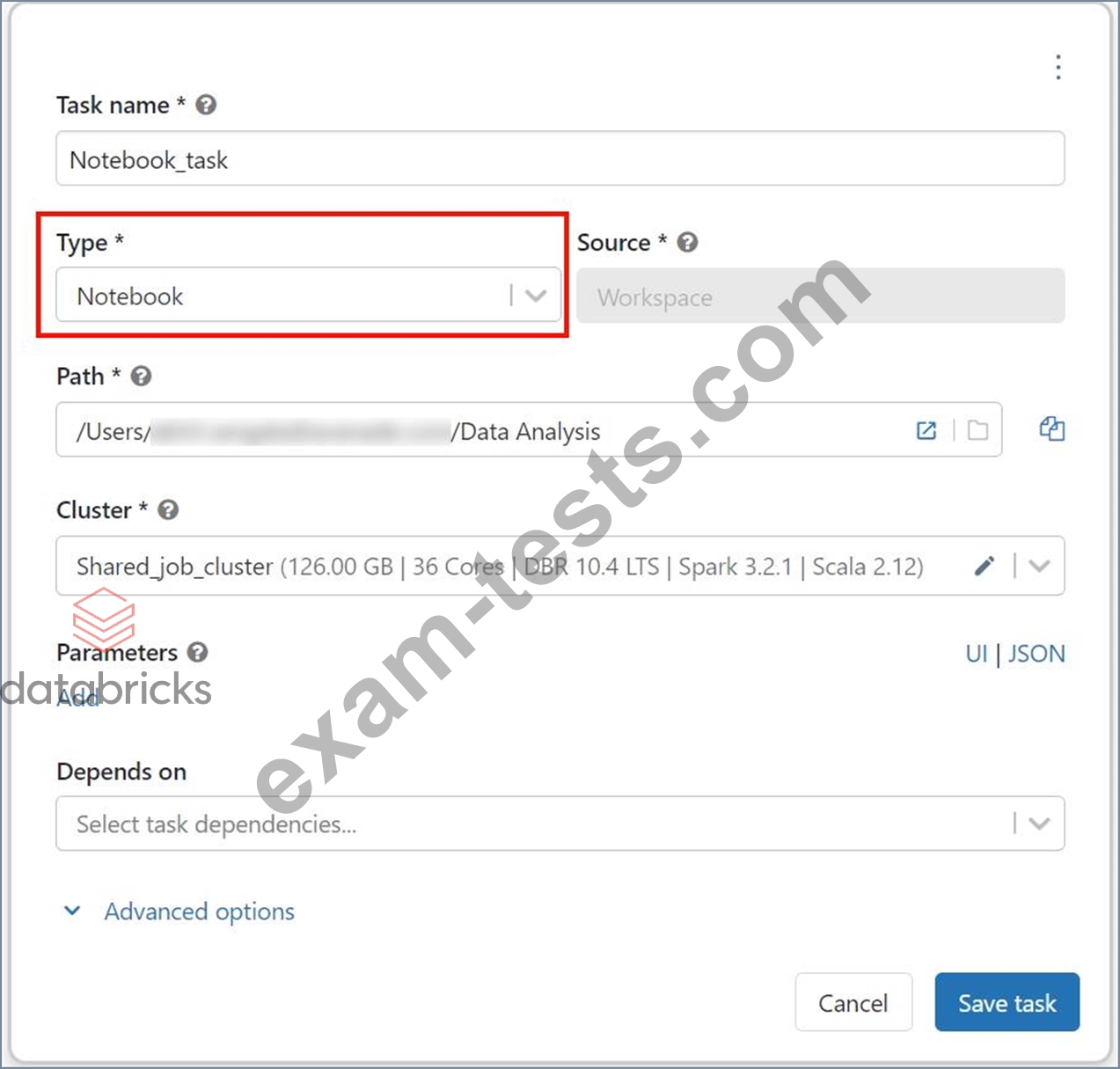
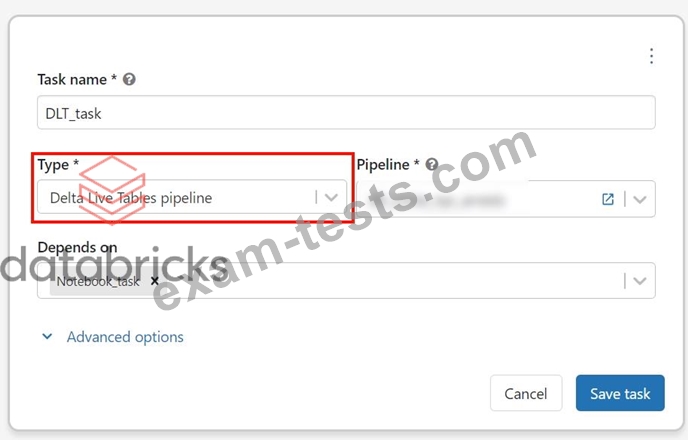
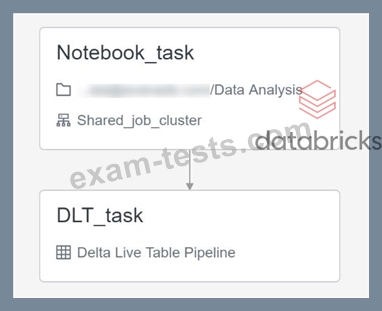
Explanation The answer is Single job can be used to set up both notebook and DLT pipeline, use two different tasks with linear dependency, Here is the JOB UI 1.Create a notebook task 2.Create DLT task a.add notebook task as dependency 3.Final view Create the notebook task Graphical user interface, text, application, email Description automatically generated DLT task Graphical user interface, text, application, email Description automatically generated Final view Graphical user interface, text, application, PowerPoint Description automatically generated Bottom of Form Top of Form
Question 42
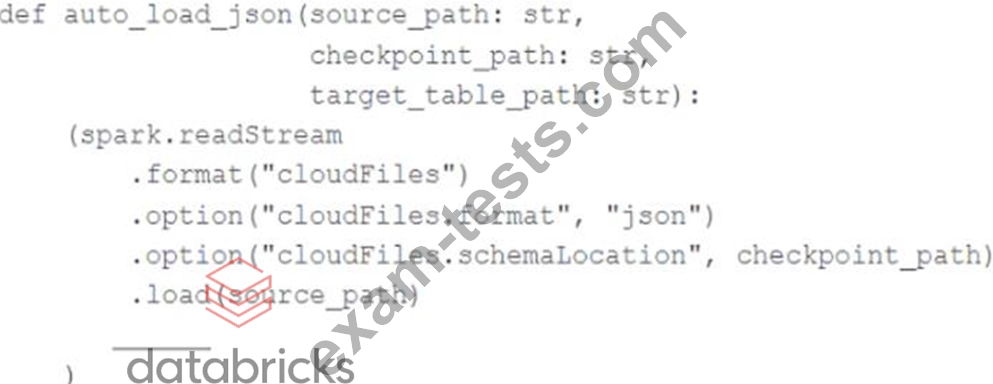
In order to facilitate near real-time workloads, a data engineer is creating a helper function to leverage the schema detection and evolution functionality of Databricks Auto Loader. The desired function will automatically detect the schema of the source directly, incrementally process JSON files as they arrive in a source directory, and automatically evolve the schema of the table when new fields are detected. The function is displayed below with a blank: Which response correctly fills in the blank to meet the specified requirements?
Correct Answer: B
Option B correctly fills in the blank to meet the specified requirements. Option B uses the "cloudFiles.schemaLocation" option, which is required for the schema detection and evolution functionality of Databricks Auto Loader. Additionally, option B uses the "mergeSchema" option, which is required for the schema evolution functionality of Databricks Auto Loader. Finally, option B uses the "writeStream" method, which is required for the incremental processing of JSON files as they arrive in a source directory. The other options are incorrect because they either omit the required options, use the wrong method, or use the wrong format. Reference: Configure schema inference and evolution in Auto Loader: https://docs.databricks.com/en/ingestion/auto-loader/schema.html Write streaming data: https://docs.databricks.com/spark/latest/structured-streaming/writing-streaming-data.html
Question 43
A Databricks job has been configured with 3 tasks, each of which is a Databricks notebook. Task A does not depend on other tasks. Tasks B and C run in parallel, with each having a serial dependency on task A. If tasks A and B complete successfully but task C fails during a scheduled run, which statement describes the resulting state?
Correct Answer: A
The query uses the CREATE TABLE USING DELTA syntax to create a Delta Lake table from an existing Parquet file stored in DBFS. The query also uses the LOCATION keyword to specify the path to the Parquet file as /mnt/finance_eda_bucket/tx_sales.parquet. By using the LOCATION keyword, the query creates an external table, which is a table that is stored outside of the default warehouse directory and whose metadata is not managed by Databricks. An external table can be created from an existing directory in a cloud storage system, such as DBFS or S3, that contains data files in a supported format, such as Parquet or CSV. The resulting state after running the second command is that an external table will be created in the storage container mounted to /mnt/finance_eda_bucket with the new name prod.sales_by_store. The command will not change any data or move any files in the storage container; it will only update the table reference in the metastore and create a new Delta transaction log for the renamed table. Verified Reference: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "ALTER TABLE RENAME TO" section; Databricks Documentation, under "Create an external table" section.
Question 44
A data engineer needs to create a database called customer360 at the loca-tion /customer/customer360. The data engineer is unsure if one of their colleagues has already created the database. Which of the following commands should the data engineer run to complete this task?
Correct Answer: B
Question 45
Consider flipping a coin for which the probability of heads is p, where p is unknown, and our goa is to estimate p. The obvious approach is to count how many times the coin came up heads and divide by the total number of coin flips. If we flip the coin 1000 times and it comes up heads 367 times, it is very reasonable to estimate p as approximately 0.367. However, suppose we flip the coin only twice and we get heads both times. Is it reasonable to estimate p as 1.0? Intuitively, given that we only flipped the coin twice, it seems a bit rash to conclude that the coin will always come up heads, and____________is a way of avoiding such rash conclusions.
Correct Answer: B
Explanation Smooth the estimates:consider flipping a coin for which the probability of heads is p, where p is unknown, and our goal is to estimate p. The obvious approach is to count how many times the coin came up heads and divide by the total number of coin flips. If we flip the coin 1000 times and it comes up heads 367 times, it is very reasonable to estimate p as approximately 0.367. However, suppose we flip the coin only twice and we get heads both times. Is it reasonable to estimate p as 1.0? Intuitively, given that we only flipped the coin twice, it seems a bit rash to conclude that the coin will always come up heads, and smoothing is a way of avoiding such rash conclusions. A simple smoothing method, called Laplace smoothing (or Laplace's law of succession or add-one smoothing in R&N), is to estimate p by (one plus the number of heads) / (two plus the total number of flips). Said differently, if we are keeping count of the number of heads and the number of tails, this rule is equivalent to starting each of our counts at one, rather than zero. Another advantage of Laplace smoothing is that it avoids estimating any probabilities to be zero, even for events never observed in the data. Laplace add-one smoothing now assigns too much probability to unseen words