Data engineering team has provided 10 queries and asked Data Analyst team to build a dashboard and refresh the data every day at 8 AM, identify the best approach to set up data refresh for this dashaboard?
Correct Answer: B
Explanation The answer is, The entire dashboard with 10 queries can be refreshed at once, single schedule needs to be set up to refresh at 8 AM. Automatically refresh a dashboard A dashboard's owner and users with the Can Edit permission can configure a dashboard to auto-matically refresh on a schedule. To automatically refresh a dashboard: * Click the Schedule button at the top right of the dashboard. The scheduling dialog appears. * Graphical user interface, text, application, email, Teams Description automatically generated * 2.In the Refresh every drop-down, select a period. * 3.In the SQL Warehouse drop-down, optionally select a SQL warehouse to use for all the queries. If you don't select a warehouse, the queries execute on the last used SQL ware-house. * 4.Next to Subscribers, optionally enter a list of email addresses to notify when the dashboard is automatically updated. * Each email address you enter must be associated with a Azure Databricks account or con-figured as an alert destination. * 5.Click Save. The Schedule button label changes to Scheduled.
Question 32
The data engineering team is migrating an enterprise system with thousands of tables and views into the Lakehouse. They plan to implement the target architecture using a series of bronze, silver, and gold tables. Bronze tables will almost exclusively be used by production data engineering workloads, while silver tables will be used to support both data engineering and machine learning workloads. Gold tables will largely serve business intelligence and reporting purposes. While personal identifying information (PII) exists in all tiers of data, pseudonymization and anonymization rules are in place for all data at the silver and gold levels. The organization is interested in reducing security concerns while maximizing the ability to collaborate across diverse teams. Which statement exemplifies best practices for implementing this system?
Correct Answer: A
This is the correct answer because it exemplifies best practices for implementing this system. By isolating tables in separate databases based on data quality tiers, such as bronze, silver, and gold, the data engineering team can achieve several benefits. First, they can easily manage permissions for different users and groups through database ACLs, which allow granting or revoking access to databases, tables, or views. Second, they can physically separate the default storage locations for managed tables in each database, which can improve performance and reduce costs. Third, they can provide a clear and consistent naming convention for the tables in each database, which can improve discoverability and usability. Verified Reference: [Databricks Certified Data Engineer Professional], under "Lakehouse" section; Databricks Documentation, under "Database object privileges" section.
Question 33
Which statement characterizes the general programming model used by Spark Structured Streaming?
Correct Answer: B
This is the correct answer because it characterizes the general programming model used by Spark Structured Streaming, which is to treat a live data stream as a table that is being continuously appended. This leads to a new stream processing model that is very similar to a batch processing model, where users can express their streaming computation using the same Dataset/DataFrame API as they would use for static data. The Spark SQL engine will take care of running the streaming query incrementally and continuously and updating the final result as streaming data continues to arrive. Verified References: [Databricks Certified Data Engineer Professional], under "Structured Streaming" section; Databricks Documentation, under "Overview" section.
Question 34
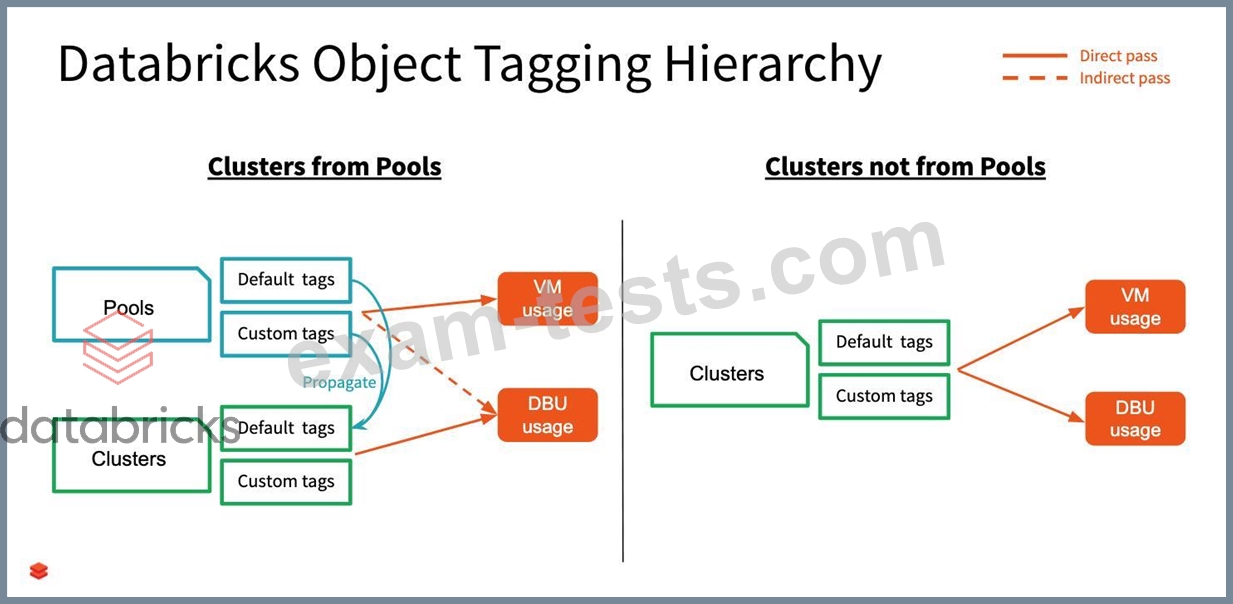
Your team has hundreds of jobs running but it is difficult to track cost of each job run, you are asked to provide a recommendation on how to monitor and track cost across various workloads
Correct Answer: B
Explanation The answer is Use Tags, during job creation so cost can be easily tracked Review below link for more details https://docs.databricks.com/administration-guide/account-settings/usage-detail-tags-aws.html Here is a view how tags get propagated from pools to clusters and clusters without pools, Diagram Description automatically generated
Question 35
Review the following error traceback: Which statement describes the error being raised?
Correct Answer: B
The error being raised is an AnalysisException, which is a type of exception that occurs when Spark SQL cannot analyze or execute a query due to some logical or semantic error1. In this case, the error message indicates that the query cannot resolve the column name 'heartrateheartrateheartrate' given the input columns 'heartrate' and 'age'. This means that there is no column in the table named 'heartrateheartrateheartrate', and the query is invalid. A possible cause of this error is a typo or a copy-paste mistake in the query. To fix this error, the query should use a valid column name that exists in the table, such as 'heartrate'. References: AnalysisException