A data engineer wants to create a relational object by pulling data from two tables. The relational object must be used by other data engineers in other sessions. In order to save on storage costs, the data engineer wants to avoid copying and storing physical data. Which of the following relational objects should the data engineer create?
Correct Answer: C
Question 2
Which of the following is the correct statement for a session scoped temporary view?
Correct Answer: A
Explanation The answer is Temporary views are lost once the notebook is detached and attached There are two types of temporary views that can be created, Session scoped and Global *A local/session scoped temporary view is only available with a spark session, so another notebook in the same cluster can not access it. if a notebook is detached and reattached local temporary view is lost. *A global temporary view is available to all the notebooks in the cluster, if a cluster restarts global temporary view is lost.
Question 3
What statement is true regarding the retention of job run history?
Correct Answer: B
Explanation This is the correct answer because it is true regarding the retention of job run history. Job run history is the information about each run of a job, such as the start time, end time, status, logs, and output. Job run history is retained for 30 days by default, during which time you can view it in the Jobs UI or access it through the Jobs API. You can also deliver job run logs to DBFS or S3 using the Log Delivery feature, which allows you to specify a destination path and a delivery frequency for each job. By delivering job run logs to DBFS or S3, you can preserve them beyond the 30-day retention period and use them for further analysis or troubleshooting. Verified References: [Databricks Certified Data Engineer Professional], under "Databricks Jobs" section;Databricks Documentation, under "Job run history" section; Databricks Documentation, under "Log Delivery" section.
Question 4
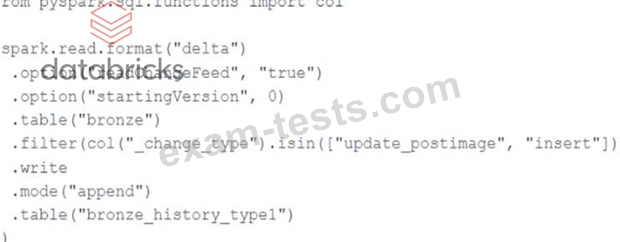
A junior data engineer seeks to leverage Delta Lake's Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in abronzetable created with the propertydelta.enableChangeDataFeed = true. They plan to execute the following code as a daily job: Which statement describes the execution and results of running the above query multiple times?
Correct Answer: C
Explanation This is the correct answer because it describes the execution and results of running the above query multiple times. The query uses the readChanges function to read all change events from a bronze table that has enabled change data feed. The readChanges function takes two arguments: version and options. The version argument specifies which version of the table to read changes from, and can be either a specific version number or -1 to indicate all versions. The options argument specifies additional options for reading changes, such as whether to include deletes or not. In this case, the query reads all changes from all versions of the bronze table and filters out delete events by setting includeDeletes to false. Then, it uses write.format("delta").mode("overwrite") to overwrite a target table using the entire history of inserted or updated records, giving the desired result of a Type 1 table representing all values that have ever been valid for all rows in the bronze table. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Read changes in batch queries" section.
Question 5
Which of the following describes how Databricks Repos can help facilitate CI/CD workflows on the Databricks Lakehouse Platform?