A Delta Lake table was created with the below query: Consider the following query: DROP TABLE prod.sales_by_store - If this statement is executed by a workspace admin, which result will occur?
Correct Answer: C
Explanation When a table is dropped in Delta Lake, the table is removed from the catalog and the data is deleted. This is because Delta Lake is a transactional storage layer that provides ACID guarantees. When a table is dropped, the transaction log is updated to reflect the deletion of the table and the data is deleted from the underlying storage. References: https://docs.databricks.com/delta/quick-start.html#drop-a-table https://docs.databricks.com/delta/delta-batch.html#drop-table
Question 127
An upstream source writes Parquet data as hourly batches to directories named with the current date. A nightly batch job runs the following code to ingest all data from the previous day as indicated by thedatevariable: Assume that the fieldscustomer_idandorder_idserve as a composite key to uniquely identify each order. If the upstream system is known to occasionally produce duplicate entries for a single order hours apart, which statement is correct?
Correct Answer: B
This is the correct answer because the code uses the dropDuplicates method to remove any duplicate records within each batch of data before writing to the orders table. However, this method does not check for duplicates across different batches or in the target table, so it is possible that newly written records may have duplicates already present in the target table. To avoid this, a better approach would be to use Delta Lake and perform an upsert operation using mergeInto. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "DROP DUPLICATES" section.
Question 128
The data engineering team maintains a table of aggregate statistics through batch nightly updates. This includes total sales for the previous day alongside totals and averages for a variety of time periods including the 7 previous days, year-to-date, and quarter-to-date. This table is named store_saies_summary and the schema is as follows: The table daily_store_sales contains all the information needed to update store_sales_summary. The schema for this table is: store_id INT, sales_date DATE, total_sales FLOAT If daily_store_sales is implemented as a Type 1 table and the total_sales column might be adjusted after manual data auditing, which approach is the safest to generate accurate reports in the store_sales_summary table?
Correct Answer: E
The daily_store_sales table contains all the information needed to update store_sales_summary. The schema of the table is: store_id INT, sales_date DATE, total_sales FLOAT The daily_store_sales table is implemented as a Type 1 table, which means that old values are overwritten by new values and no history is maintained. The total_sales column might be adjusted after manual data auditing, which means that the data in the table may change over time. The safest approach to generate accurate reports in the store_sales_summary table is to use Structured Streaming to subscribe to the change data feed for daily_store_sales and apply changes to the aggregates in the store_sales_summary table with each update. Structured Streaming is a scalable and fault-tolerant stream processing engine built on Spark SQL. Structured Streaming allows processing data streams as if they were tables or DataFrames, using familiar operations such as select, filter, groupBy, or join. Structured Streaming also supports output modes that specify how to write the results of a streaming query to a sink, such as append, update, or complete. Structured Streaming can handle both streaming and batch data sources in a unified manner. The change data feed is a feature of Delta Lake that provides structured streaming sources that can subscribe to changes made to a Delta Lake table. The change data feed captures both data changes and schema changes as ordered events that can be processed by downstream applications or services. The change data feed can be configured with different options, such as starting from a specific version or timestamp, filtering by operation type or partition values, or excluding no-op changes. By using Structured Streaming to subscribe to the change data feed for daily_store_sales, one can capture and process any changes made to the total_sales column due to manual data auditing. By applying these changes to the aggregates in the store_sales_summary table with each update, one can ensure that the reports are always consistent and accurate with the latest data. Verified References: [Databricks Certified Data Engineer Professional], under "Spark Core" section; Databricks Documentation, under "Structured Streaming" section; Databricks Documentation, under "Delta Change Data Feed" section.
Question 129
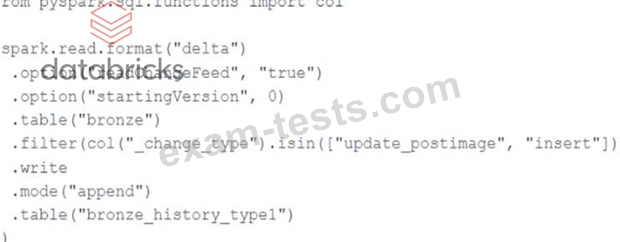
A junior data engineer seeks to leverage Delta Lake's Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in abronzetable created with the propertydelta.enableChangeDataFeed = true. They plan to execute the following code as a daily job: Which statement describes the execution and results of running the above query multiple times?
Correct Answer: B
Explanation Reading table's changes, captured by CDF, using spark.read means that you are reading them as a static source. So, each time you run the query, all table's changes (starting from the specified startingVersion) will be read.
Question 130
A Delta Lake table representing metadata about content posts from users has the following schema: * user_id LONG * post_text STRING * post_id STRING * longitude FLOAT * latitude FLOAT * post_time TIMESTAMP * date DATE Based on the above schema, which column is a good candidate for partitioning the Delta Table?
Correct Answer: A
Partitioning a Delta Lake table is a strategy used to improve query performance by dividing the table into distinct segments based on the values of a specific column. This approach allows queries to scan only the relevant partitions, thereby reducing the amount of data read and enhancing performance. Considerations for Choosing a Partition Column: * Cardinality:Columns with high cardinality (i.e., a large number of unique values) are generally poor choices for partitioning. High cardinality can lead to a large number of small partitions, which can degrade performance. * Query Patterns:The partition column should align with common query filters. If queries frequently filter data based on a particular column, partitioning by that column can be beneficial. * Partition Size:Each partition should ideally contain at least 1 GB of data. This ensures that partitions are neither too small (leading to too many partitions) nor too large (negating the benefits of partitioning). Evaluation of Columns: * date: * Cardinality:Typically low, especially if data spans over days, months, or years. * Query Patterns:Many analytical queries filter data based on date ranges. * Partition Size:Likely to meet the 1 GB threshold per partition, depending on data volume. * user_id: * Cardinality:High, as each user has a unique ID. * Query Patterns:While some queries might filter by user_id, the high cardinality makes it unsuitable for partitioning. * Partition Size:Partitions could be too small, leading to inefficiencies. * post_id: * Cardinality:Extremely high, with each post having a unique ID. * Query Patterns:Unlikely to be used for filtering large datasets. * Partition Size:Each partition would be very small, resulting in a large number of partitions. * post_time: * Cardinality:High, especially if it includes exact timestamps. * Query Patterns:Queries might filter by time, but the high cardinality poses challenges. * Partition Size:Similar to user_id, partitions could be too small. Conclusion: Given the considerations, the date column is the most suitable candidate for partitioning. It has low cardinality, aligns with common query patterns, and is likely to result in appropriately sized partitions. References: * Delta Lake Best Practices * Partitioning in Delta Lake